
Today we’re introducing the Superficial API — our first product milestone on the path to reliable artificial intelligence.
Over the past decade, neural networks like the large language models many of us use daily, have transformed how we interact with information. These systems are now capable of assisting with increasingly complex tasks across a wide range of domains. But while their capabilities continue to expand, one problem remains unresolved: they make mistakes.
The best models today make errors in ~38% of the claims they make. The only current remedy is human intervention — reading carefully, checking line by line, stepping in to fix what goes wrong. This works in low-risk settings, but it doesn’t scale to the world AI is entering.
As AI systems move from being passive assistants to acting on our behalf, these errors don’t just mislead. They cascade. They compound. They occur at machine speeds that make human correction too slow to be effective.
This is the challenge Superficial was built to solve.
Superficial builds on decades of research in neural-symbolic computing — including foundational work on integrating learning and reasoning by Garcez et al. (2019) and recent advances in verifiable neuro-symbolic systems by Yu et al. (2023) — to release the first neurosymbolic system designed to make neural AI outputs verifiable, auditable, and reliable at scale. Superficial combines both strands of AI to eliminate the limitations of purely neural systems by combining fast, adaptive neural perception with structured, deterministic symbolic reasoning.
Across more than 55,000 claims from the Google DeepMind FACTS dataset, Superficial boosts the average accuracy of top AI models to 99.7% — a 9.9% relative improvement. Many of today's top models, including GPT-5, Grok 4, Gemini 2.5 Flash and gpt-oss score 100% after Superficial one-shot enhancement.
This makes it possible, for the first time, to embed verification directly into AI workflows and guarantee reliability at machine speed.
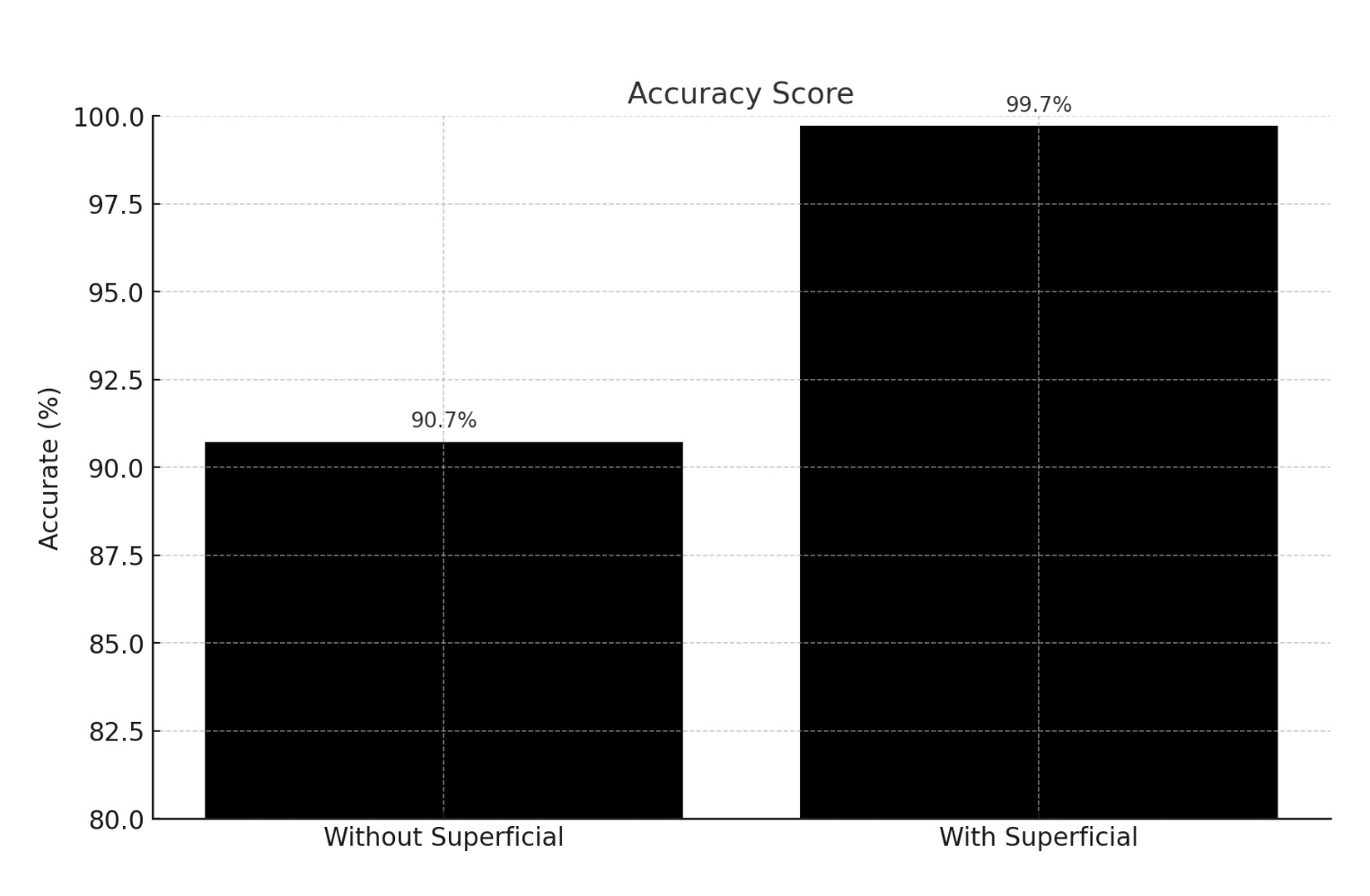
Source: Superfacts Benchmark (benchmarks.superficial.org). Real-world accuracy depends on source availability and domain complexity.
How we got here: Overcoming the brittleness of symbolic systems
Symbolic AI has long offered the promise of logic, traceability, and interpretability. But in practice, symbolic systems have proven brittle. They rely on predefined rules, making them fragile in real-world settings where language is ambiguous, inputs are noisy, and new concepts appear constantly. This rigidity has historically limited symbolic reasoning to narrow domains with carefully structured data.
Superficial removes this barrier. By pairing neural flexibility with symbolic structure, it establishes a general-purpose verification layer that can adapt dynamically to unpredictable, open-world inputs — without sacrificing determinism or auditability.
How Superficial Delivers Verifiable Accuracy
To reliably audit a "black box" AI, you can't just ask it if it's right. You need a transparent, deterministic, and repeatable process. Superficial provides this by breaking verification into five distinct stages, moving from messy neural output to auditable, symbolic proof.
1. Deconstruction
We start by taking complex, neural-generated output and deconstructing it into its smallest, independently verifiable parts. Our fine-tuned models parse model responses to extract atomic claims—discrete, self-contained assertions. This crucial first step eliminates ambiguity, reduces compounding errors, and allows us to test each individual statement.
2. Policy Classification
Not all claims are equal, and they shouldn't be verified the same way. Once a claim is isolated, our policy classifier analyzes its semantic structure and automatically selects the correct verification policy from our policy library. This could be a generic factual check, a query against a specific legal statute, or a custom policy unique to your company.
3. Grounding
With a claim and a policy in hand, our system finds the evidence. The Grounding engine performs a high-precision semantic search against your designated sources—be it the public web, a specific set of documents (like financial filings), or an internal database. It retrieves only the most relevant text spans required to execute the verification.
4. Verification
This is the critical step where the "black box" becomes transparent. Instead of using one LLM to "guess" at another's accuracy, Superficial executes the selected policy against the grounding text using deterministic, non-LLM reasoning. This symbolic verification process runs like a program, not an opinion.
The result is a simple, reliable, and consistent output: Confirmed, Refuted, or Inconclusive, complete with a traceable justification and a direct reference to the source. It is 100% explainable and auditable.
5. Training Data Generation
Verification isn't just a grade; it's a tool for improvement. Superficial automatically packages all refuted and inconclusive claims into structured, high-quality training data (JSONL) allowing your team to easily re-train your model, fix entire classes of errors, and demonstrably improve its accuracy over time. We turn your model's failures into its most valuable training asset.
This five-step process is the core innovation behind Superficial. By systematically deconstructing neural content, applying dynamic policies, and using deterministic logic for the final verification, we make it possible to perform reliable, auditable reasoning over unpredictable AI-generated content.
Superficial API available now in preview
We’re opening early access to the Superficial API for selected teams and individuals.
Reach out to us at contact@superficial.org to request access to the API.
We believe that the future of AI doesn’t require choosing between capability and reliability. With the right infrastructure, we can build systems that are both. The Superficial API is our first step on this path.